处理中断和陷入
概述
如果我们从来不会出差错,那不是很好吗?嗯,很不好,这是不可能的。所以,我们需要在问题发生时做好准备。 CPU 能够在事情发生时通知内核。虽说如此,并非所有的通知都是坏事。比如系统调用,或者定时器中断呢?是的,这些也会导致 CPU 通知内核。
RISC-V中断系统
RISC-V 系统使用一个单一的、指向内核中的物理地址的函数指针。每当有事情发生时,CPU 会切换到机器态并跳转到这个函数。在 RISC-V 中,我们有两个特殊的 CSR(控制和状态寄存器)来控制这种 CPU 通信。
第一个寄存器是 mtvec 寄存器,它代表了机器陷入向量。向量是一个函数指针。每当有事情发生, CPU 就会“调用”这个寄存器所表示的函数。
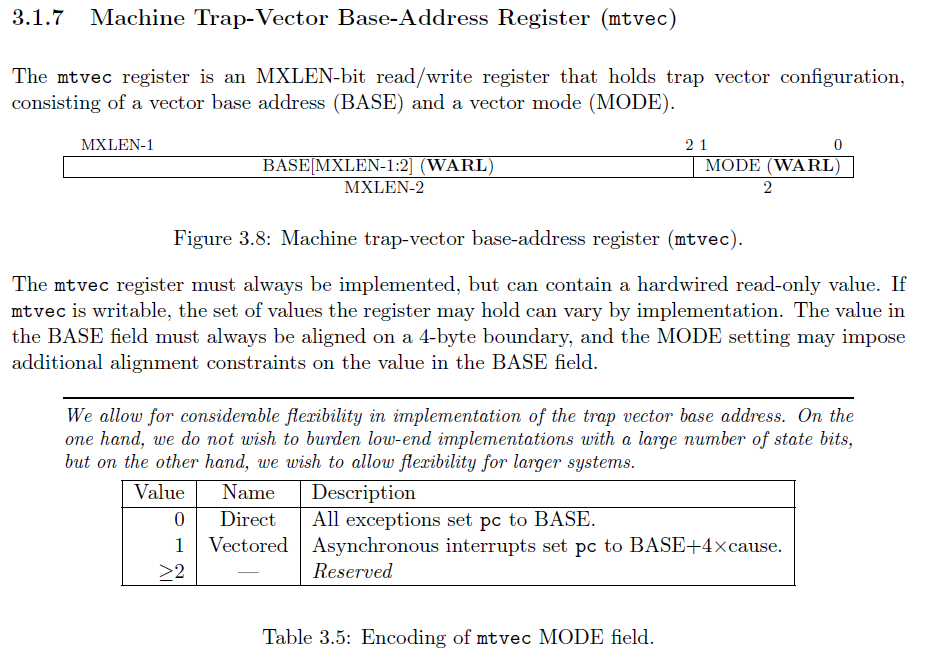
mtvec 寄存器有两个不同的字段。BASE ,也就是函数的地址,以及 MODE,它决定了我们是要使用直接中断还是向量中断。我们要使用 Rust 的 match 来重定向陷入。所以我们需要确保最后两位是 0 ,这意味着我们的函数地址需要是 4 的倍数。
使用直接模式的 mtvec 意味着所有的陷入都会进入完全相同的函数,而使用矢量模式的 mtvec 会根据陷入原因进入不同的函数。简单起见,我将使用直接模式。然后,我们可以使用 Rust 的 match 语句解析出陷入原因。
为什么陷入?
mcause 寄存器(机器态陷入原因)会给你一个异常代码,概括地解释是什么导致了陷入。陷入有两种不同的类型:异步的和同步的。异步陷入意味着是当前执行的指令之外的东西引起了 CPU 的“陷入”。同步陷入意味着是当前执行的指令引起了“陷入”。
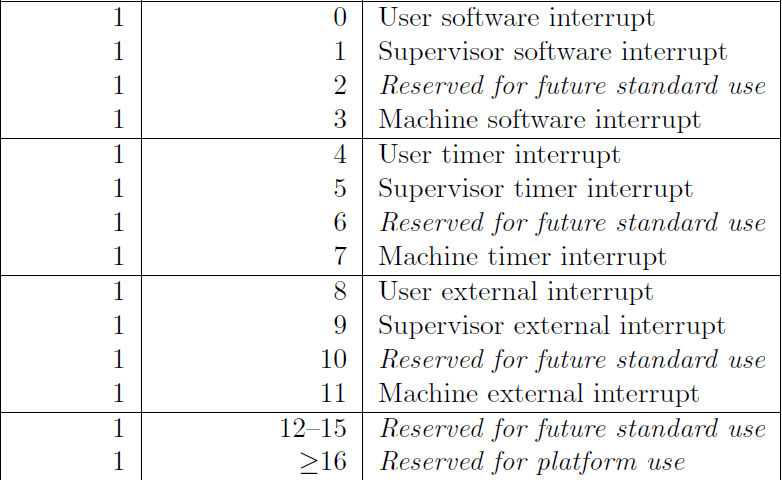
异步陷入的原因代码最高位一定为 1。
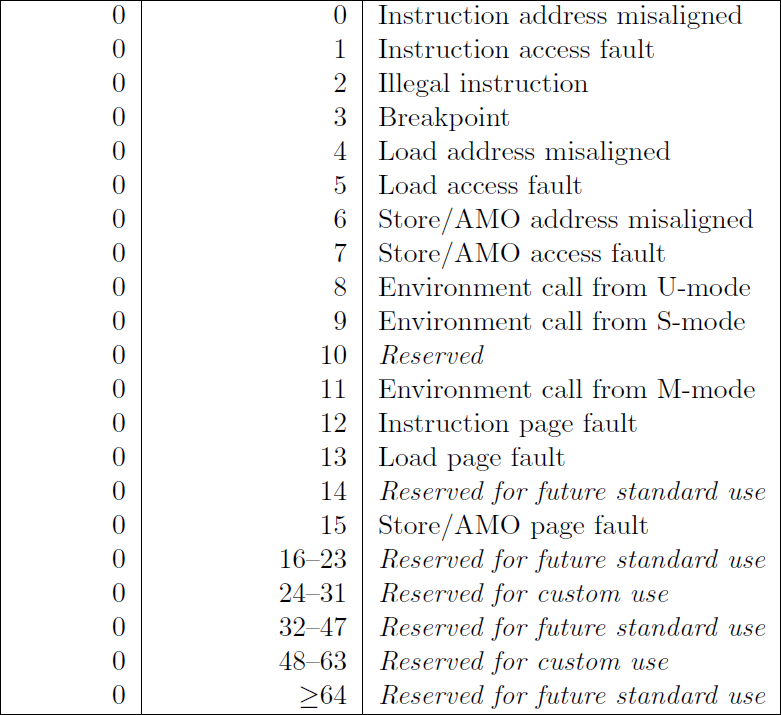
异步陷入的原因代码最高位一定为 0。
简单启动
我对启动代码进行了修改以简化启动过程。我们通过 kinit 进入 Rust,它在仅有物理内存的机器态下运行代码。在这个函数中,我们基本上可以自任意支配我们的系统。然而, kinit 的意义在于让我们尽快进入 kmain 。我们将在内核态下运行 kmain 函数,在这种模式下,我们的内核开启了虚拟内存。
# We need a stack for our kernel. This symbol comes from virt.lds
la sp, _stack_end
# Setting `mstatus` register:
# 0b01 << 11: Machine's previous protection mode is 2 (MPP=2).
li t0, 0b11 << 11
csrw mstatus, t0
# Do not allow interrupts while running kinit
csrw mie, zero
# Machine's exception program counter (MEPC) is set to `kinit`.
la t1, kinit
csrw mepc, t1
# Set the return address to get us into supervisor mode
la ra, 2f
# We use mret here so that the mstatus register is properly updated.
mret
我们的代码设置好了机器态环境。我们在 mie 中写入 0,也就是“机器态中断使能寄存器”,以禁用所有的中断。因此, kinit 处于机器态,只有物理内存,并且现在是不可抢占的。这使我们能够设置我们的机器,而不必担心其他的硬件线程(核)会干扰我们的进程。
陷入
陷入本质上是 CPU 通知内核的一种方式。通常情况下,我们作为内核程序员告诉 CPU 正在发生什么。然而,有时 CPU 需要让我们知道发生了什么。如上所述,它是通过一个陷入来实现的。所以,为了在 Rust 中处理陷入,我们需要创建一个新的文件, trap.rs 。
#![allow(unused)] fn main() { // trap.rs // Trap routines // Stephen Marz // 10 October 2019 use crate::cpu::TrapFrame; #[no_mangle] extern "C" fn m_trap(epc: usize, tval: usize, cause: usize, hart: usize, status: usize, frame: &mut TrapFrame) -> usize { // We're going to handle all traps in machine mode. RISC-V lets // us delegate to supervisor mode, but switching out SATP (virtual memory) // gets hairy. let is_async = { if cause >> 63 & 1 == 1 { true } else { false } }; // The cause contains the type of trap (sync, async) as well as the cause // number. So, here we narrow down just the cause number. let cause_num = cause & 0xfff; let mut return_pc = epc; if is_async { // Asynchronous trap match cause_num { 3 => { // Machine software println!("Machine software interrupt CPU#{}", hart); }, 7 => unsafe { // Machine timer let mtimecmp = 0x0200_4000 as *mut u64; let mtime = 0x0200_bff8 as *const u64; // The frequency given by QEMU is 10_000_000 Hz, so this sets // the next interrupt to fire one second from now. mtimecmp.write_volatile(mtime.read_volatile() + 10_000_000); }, 11 => { // Machine external (interrupt from Platform Interrupt Controller (PLIC)) println!("Machine external interrupt CPU#{}", hart); }, _ => { panic!("Unhandled async trap CPU#{} -> {}\n", hart, cause_num); } } } else { // Synchronous trap match cause_num { 2 => { // Illegal instruction panic!("Illegal instruction CPU#{} -> 0x{:08x}: 0x{:08x}\n", hart, epc, tval); }, 8 => { // Environment (system) call from User mode println!("E-call from User mode! CPU#{} -> 0x{:08x}", hart, epc); return_pc += 4; }, 9 => { // Environment (system) call from Supervisor mode println!("E-call from Supervisor mode! CPU#{} -> 0x{:08x}", hart, epc); return_pc += 4; }, 11 => { // Environment (system) call from Machine mode panic!("E-call from Machine mode! CPU#{} -> 0x{:08x}\n", hart, epc); }, // Page faults 12 => { // Instruction page fault println!("Instruction page fault CPU#{} -> 0x{:08x}: 0x{:08x}", hart, epc, tval); return_pc += 4; }, 13 => { // Load page fault println!("Load page fault CPU#{} -> 0x{:08x}: 0x{:08x}", hart, epc, tval); return_pc += 4; }, 15 => { // Store page fault println!("Store page fault CPU#{} -> 0x{:08x}: 0x{:08x}", hart, epc, tval); return_pc += 4; }, _ => { panic!("Unhandled sync trap CPU#{} -> {}\n", hart, cause_num); } } }; // Finally, return the updated program counter return_pc } }
上面的代码就是我们在陷入时跳转到的函数。CPU 遇到一个陷入,找到 mtvec ,然后跳转到其中指定的地址。注意,我们必须先解析出中断类型(异步或同步),然后再解析其原因。
请注意,我们有三个期望的同步异常: 8 、 9 和 11 。这些是“环境”调用,也就是系统调用。然而,原因是根据我们在发出 ecall 指令时所处的模式来解析的。我对机器态的 ecall 调用了 panic! ,因为我们永远不应该遇到一个机器态的 ecall 。相反,我们在内核态下运行内核,而用户应用程序将通过用户态的 ecall 进入内核。
当我们遇到一个陷入时,我们需要跟踪我们的寄存器等等。我们如果在一开始就搞乱了寄存器,就没有办法再重新启动一个用户应用。我们将把这些信息保存到一个叫做陷入帧的东西中。我们还将使用 mscratch 寄存器来存储这些信息,这样当我们遇到陷入的时候就很容易找到它。
陷入帧 Rust 结构体
#![allow(unused)] fn main() { #[repr(C)] #[derive(Clone, Copy)] pub struct TrapFrame { pub regs: [usize; 32], // 0 - 255 pub fregs: [usize; 32], // 256 - 511 pub satp: usize, // 512 - 519 pub trap_stack: *mut u8, // 520 pub hartid: usize, // 528 } }
如上述结构体所示,我们存储了所有的通用寄存器、浮点寄存器、SATP(MMU)、处理陷入的堆栈,以及硬件线程 ID 。当我们只使用机器态的陷入时,最后一项是不必要的。RISC-V 允许我们将某些陷入委托给内核态。然而,我们还没有这样做。目前 hartid 是多余的,因为我们可以通过 csrr a0, mhartid 获得硬件线程 ID。
你还会注意到两个 Rust 指令: #[repr(C)] 和 #[derive(Clone, Copy)] 。第一个指令使我们的结构体遵循 C 语言风格的结构体。这么做是因为当我们在汇编中操作陷入帧时,我们需要知道每个成员变量的偏移量。最后, derive 指令将使 Rust 自动实现 Copy 和 Clone 的特性。如果我们不使用 derive ,我们就得自己实现。
现在我们已经建立起了陷入帧,让我们看看它在汇编中的样子。
查看汇编中的陷入向量
.option norvc
m_trap_vector:
# All registers are volatile here, we need to save them
# before we do anything.
csrrw t6, mscratch, t6
# csrrw will atomically swap t6 into mscratch and the old
# value of mscratch into t6. This is nice because we just
# switched values and didn't destroy anything -- all atomically!
# in cpu.rs we have a structure of:
# 32 gp regs 0
# 32 fp regs 256
# SATP register 512
# Trap stack 520
# CPU HARTID 528
# We use t6 as the temporary register because it is the very
# bottom register (x31)
.set i, 1
.rept 30
save_gp %i
.set i, i+1
.endr
# Save the actual t6 register, which we swapped into
# mscratch
mv t5, t6
csrr t6, mscratch
save_gp 31, t5
# Restore the kernel trap frame into mscratch
csrw mscratch, t5
# Get ready to go into Rust (trap.rs)
# We don't want to write into the user's stack or whomever
# messed with us here.
csrr a0, mepc
csrr a1, mtval
csrr a2, mcause
csrr a3, mhartid
csrr a4, mstatus
mv a5, t5
ld sp, 520(a5)
call m_trap
# When we get here, we've returned from m_trap, restore registers
# and return.
# m_trap will return the return address via a0.
csrw mepc, a0
# Now load the trap frame back into t6
csrr t6, mscratch
# Restore all GP registers
.set i, 1
.rept 31
load_gp %i
.set i, i+1
.endr
# Since we ran this loop 31 times starting with i = 1,
# the last one loaded t6 back to its original value.
mret
你可以看到我们使用了所谓的汇编器指令和宏,例如 .set 和 store_gp ,这使我们的生活更轻松。这本质上是一个汇编时的循环,当我们汇编这个文件时会被展开。
我们还指定了 .option norvc ,意思是"RISC-V压缩指令",它是RISC-V ISA 的 C 扩展。这强制要求所有用于陷入向量的指令都是 32 位的。这不是特别重要,但是当我们添加多个陷入向量时,我们需要确保每个向量函数都从 4 的整数倍的内存地址开始。这是因为 mtvec 寄存器使用最后两位在直接模式和向量模式间切换。
GNU 汇编宏
宏的定义如下。
.altmacro
.set NUM_GP_REGS, 32 # Number of registers per context
.set NUM_FP_REGS, 32
.set REG_SIZE, 8 # Register size (in bytes)
.set MAX_CPUS, 8 # Maximum number of CPUs
# Use macros for saving and restoring multiple registers
.macro save_gp i, basereg=t6
sd x\i, ((\i)*REG_SIZE)(\basereg)
.endm
.macro load_gp i, basereg=t6
ld x\i, ((\i)*REG_SIZE)(\basereg)
.endm
.macro save_fp i, basereg=t6
fsd f\i, ((NUM_GP_REGS+(\i))*REG_SIZE)(\basereg)
.endm
.macro load_fp i, basereg=t6
fld f\i, ((NUM_GP_REGS+(\i))*REG_SIZE)(\basereg)
.endm
讲解上面的宏已经超出了本博客的范围,但值得一提的是,我们正在执行以下指令之一: sd, ld, fsd, fld ,并且默认情况下,我们使用 t6 寄存器。我选择 t6 寄存器的原因是它是 31 号寄存器,这使得我们很容易追踪到我们从寄存器 0 一直运行到 31 的循环。
这有什么作用?
陷入是由CPU引起的。每个硬件线程都可以产生陷入,所以我们之后需要进行互斥和推迟行动。
当你运行这段代码时,应该看到下面的输出。
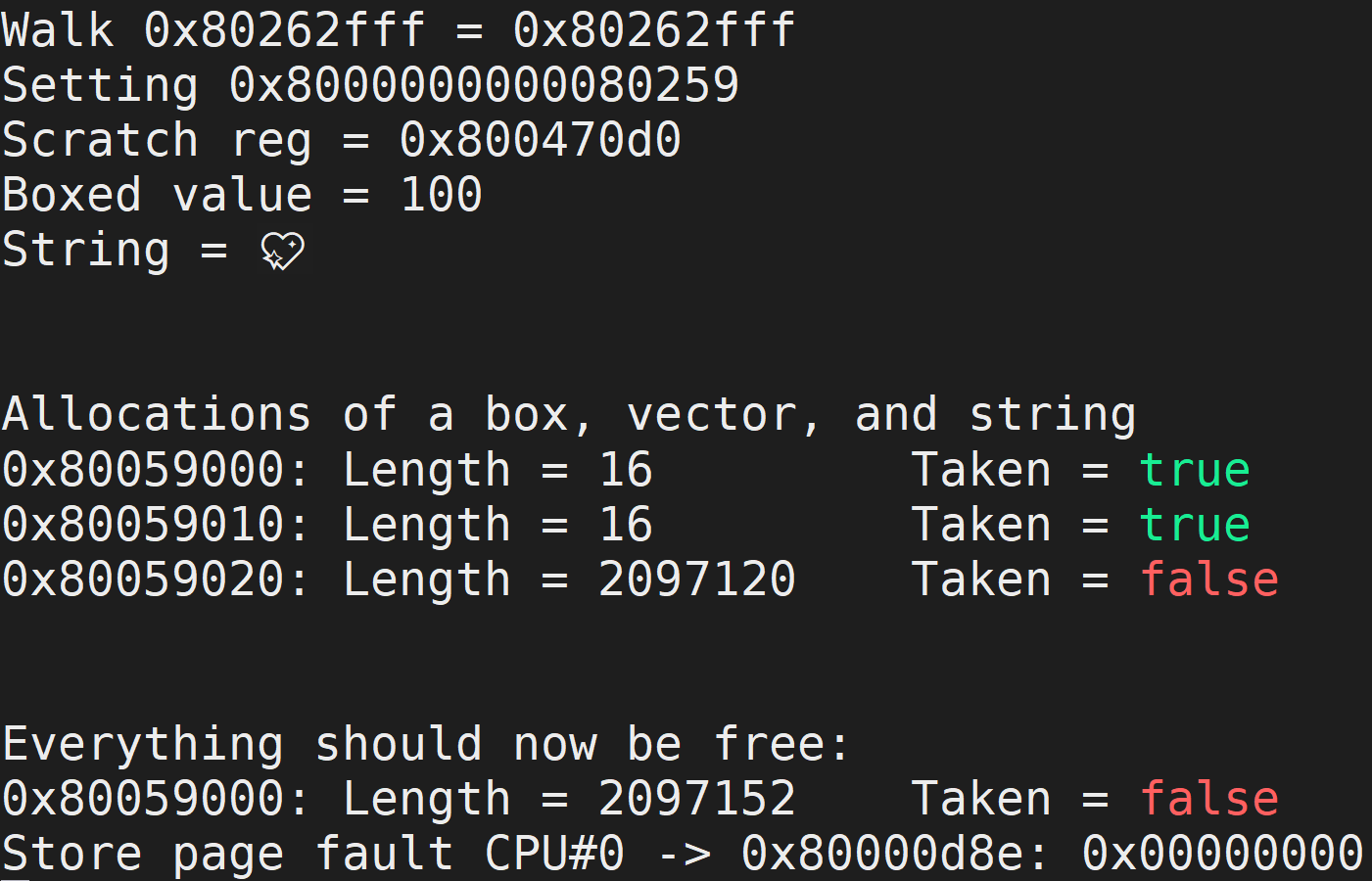
你会注意到,在底部有一个页面错误。这是有意为之,因为我已经在 Rust 代码中加入了以下内容。这几乎确保了页面错误的发生!
#![allow(unused)] fn main() { unsafe { // Set the next machine timer to fire. let mtimecmp = 0x0200_4000 as *mut u64; let mtime = 0x0200_bff8 as *const u64; // The frequency given by QEMU is 10_000_000 Hz, so this sets // the next interrupt to fire one second from now. mtimecmp.write_volatile(mtime.read_volatile() + 10_000_000); // Let's cause a page fault and see what happens. This should trap // to m_trap under trap.rs let v = 0x0 as *mut u64; v.write_volatile(0); } }
第一部分重置了CLINT定时器,这将触发一个异步机器定时器陷入。然后,我们对 NULL 指针解引用,这将导致我们的存储页面错误。如果是 v.read_volatile() ,我们会得到一个载入页面错误而非存储。